The Dots Game
A research-driven project exploring AI strategies for the Dots game, combining Rust-based algorithm implementations with a web interface and Python analytics. The work evaluates MCTS and MiniMax variants across thousands of simulations, offering insights into search efficiency on large and dynamic boards.
Evaluation of Minimax and Monte Carlo Tree Search for General Game Playing using the game of Dots#
Overview#
This project explores how two major decision-making algorithms-Monte Carlo Tree Search (MCTS) and MiniMax (with alpha-beta pruning)-perform in Dots, a high-branching-factor strategy game. The goal was to understand how these algorithms behave both with and without domain-specific heuristics, and whether classic game-AI techniques translate effectively to a less-studied combinatorial game.
A custom Rust game engine was built to simulate thousands of matches under controlled but varied conditions (board size, time limits, initial randomness). The algorithms were tested fairly by giving them identical constraints and no access to hidden information.
The Game: Dots#
Dots is a two-player territory-control game. Players alternate placing dots on a grid, trying to surround and capture enemy dots while protecting their own. Captures grant points; the highest score wins when the board is full.
Although simple to describe, the game has a very high branching factor, making brute-force exploration difficult and rewarding long-term planning and spatial strategy.
Key Strategies in Dots#
While designing evaluators, two standout strategies emerged from gameplay:
-
Traps
Small 4-dot structures that force the opponent to step into a losing position during the endgame. -
Walls
Chains of connected dots that divide the board and protect territory-especially powerful when anchored to the board’s edges.
These ideas later shaped several MiniMax evaluators.
Methodology#
Algorithms Tested#
-
MiniMax
Deterministic search with iterative deepening & transposition tables. -
MiniMax + Alpha-Beta Pruning
Same as above, but efficiently cuts unneeded branches. -
MCTS (UCT variant)
Stochastic simulation-based search, ideal for large search spaces. -
Neural-Network-Guided MCTS (AlphaZero-inspired)
A lightweight version using a small network trained through self-play.
Evaluation Functions (Depth-First Search Only)#
Algorithms were tested with multiple evaluators:
- Score-based (no game knowledge)
- Noise-enhanced (adds mild randomness)
- Trap-focused
- Checkerboard pattern
- Wall-building
Simulation Parameters#
Each match randomized:
- Board size: 10×10, 20×20
- Initial random dots: 5 or 10
- Time per move: 10ms, 50ms, 100ms, 500ms
- Who plays first
In total:
- 1100+ algorithm-vs-algorithm games
- 3200 evaluator tests
- 2600 MCTS vs MiniMax (best evaluator) games
Results#
Across all simulations, several clear patterns emerged, reflecting how each algorithm handled complexity, randomness, and branching factor.
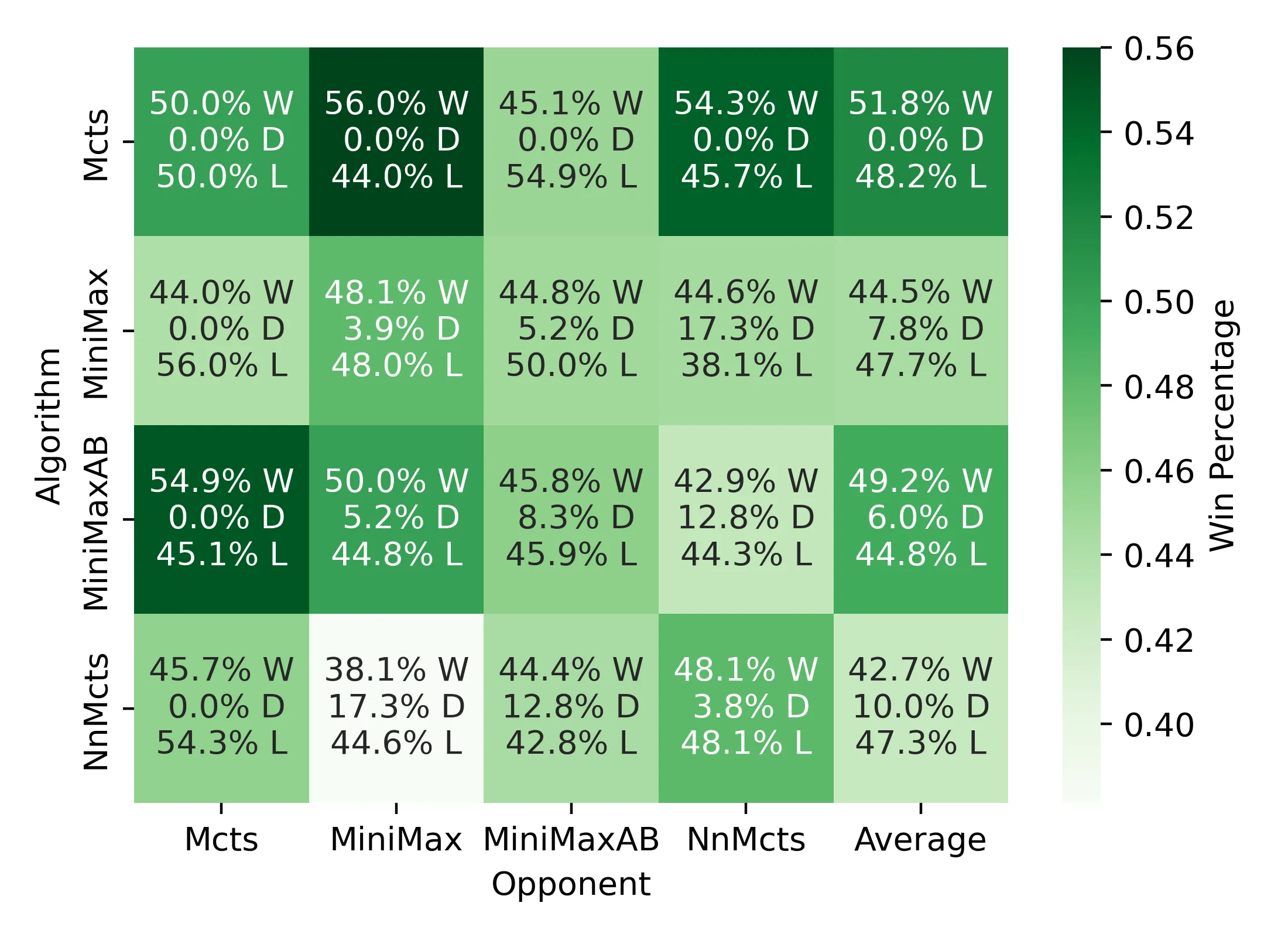
1. MCTS consistently outperforms plain MiniMax#
MCTS was stronger across most settings, particularly when the board was large, the number of legal moves was high, or the per-move time budget was small. Its stochastic rollouts allowed it to find promising lines of play even when MiniMax collapsed under the exponential branching factor.
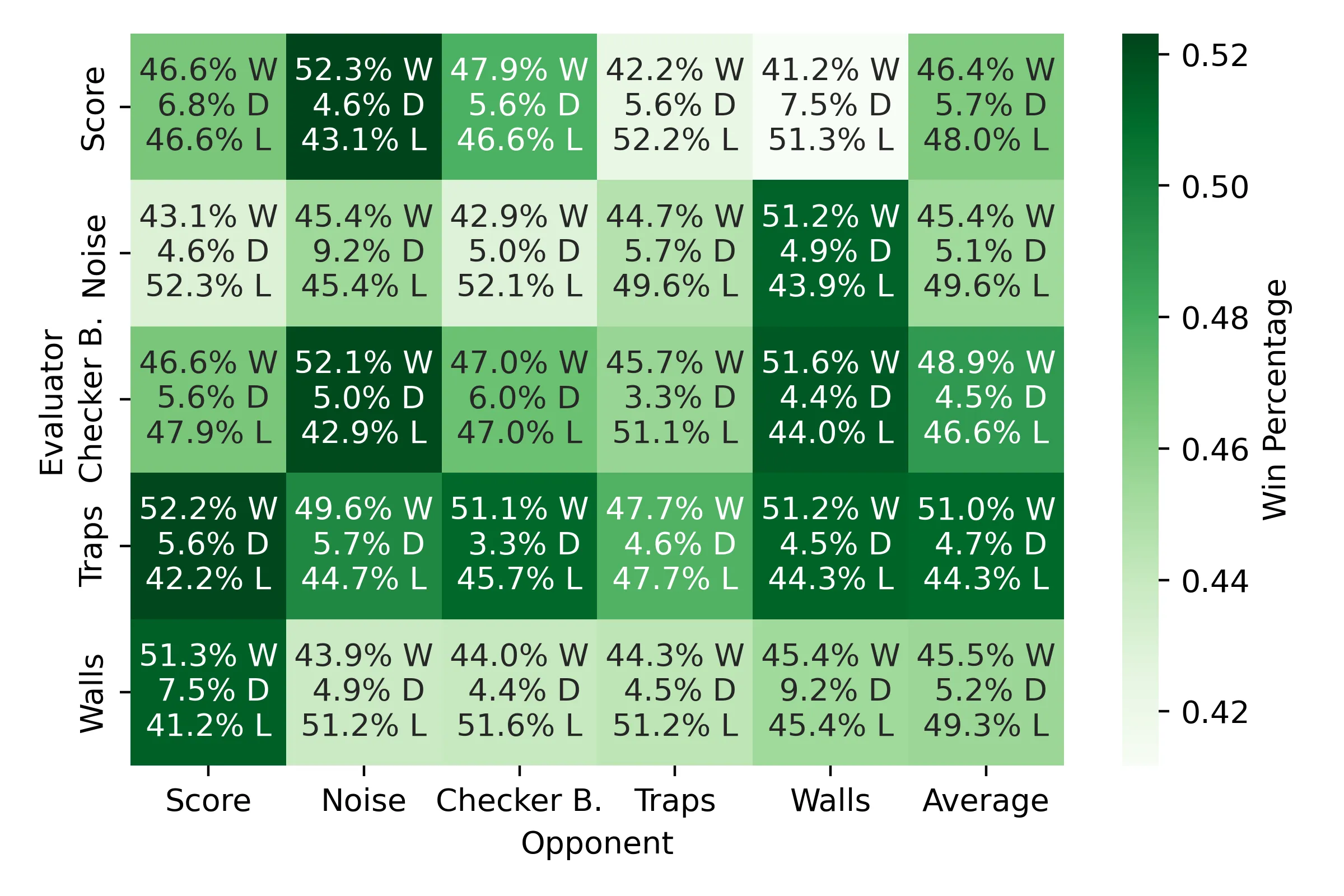
2. Domain knowledge dramatically improves MiniMax#
Once MiniMax was equipped with heuristics reflecting the structure of Dots, its performance lifted substantially. Among all evaluators, the trap-focused heuristic performed best, since traps reliably convert positional advantages into guaranteed points in late-game states. Other evaluators-like Walls, Checkerboard, and Noise-showed situational strengths but did not generalize as well.
3. Even against improved MiniMax, MCTS remains the strongest overall#
Although MiniMax with domain knowledge closed the gap, MCTS still won most long-run matchups. Its ability to explore diverse outcomes proved especially valuable when openings became chaotic due to randomness or when mid-game states expanded beyond deterministic search depth.
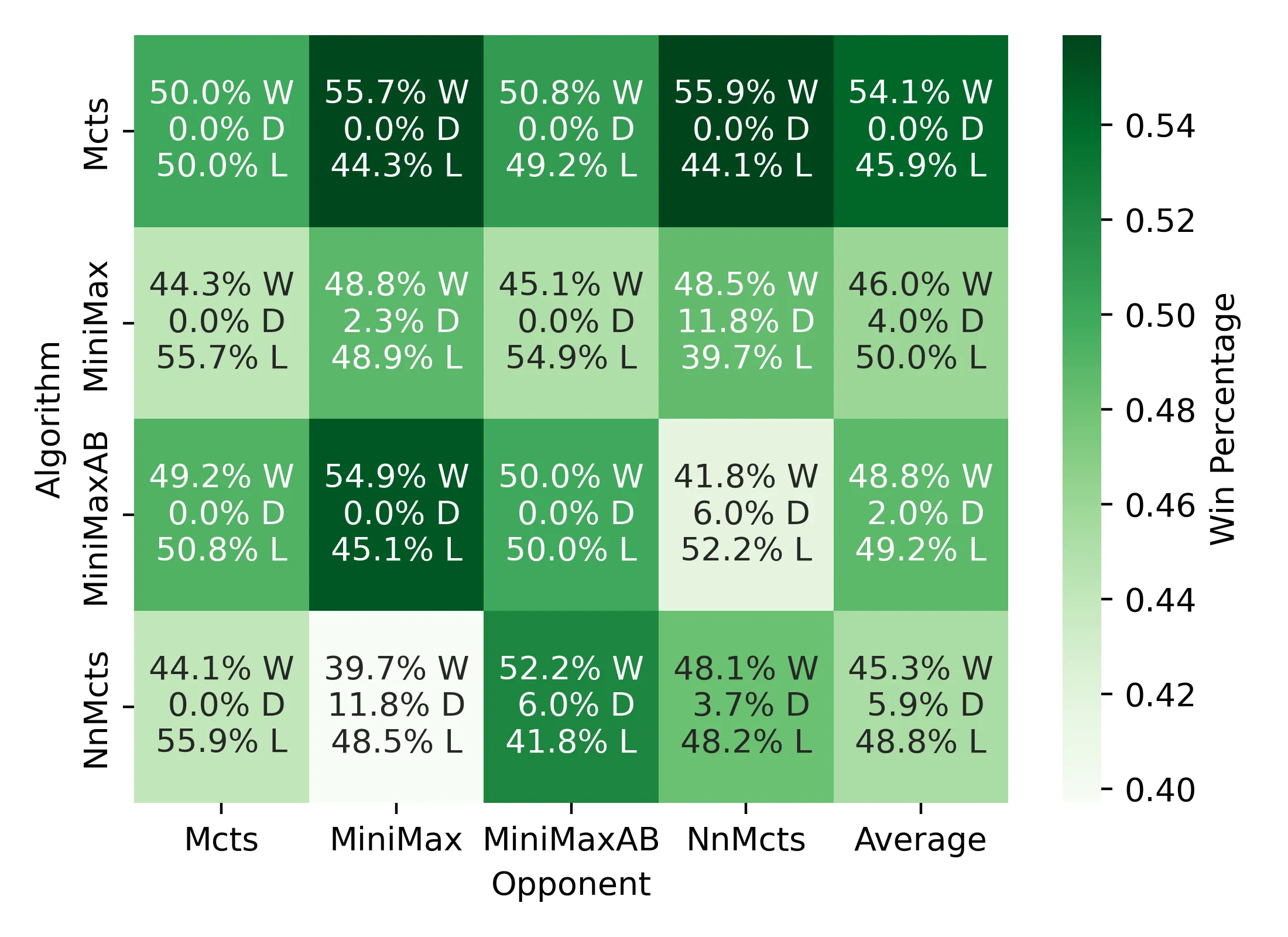
4. Larger boards amplify algorithmic differences#
On 20×20 boards, the search space grows so rapidly that MiniMax-even with aggressive pruning-struggles to maintain evaluative accuracy. MCTS, by contrast, benefits from the additional room to explore and converges more consistently toward strong moves. The larger the board, the more pronounced this advantage becomes.
Findings#
Across all experiments, several consistent patterns emerged. MCTS showed strong general performance, especially in configurations with high branching factors, larger boards, or increased initial randomness. Its ability to adapt to diverse states allowed it to overcome poor openings and recover from unpredictable early-game setups. MiniMax, in contrast, struggled in the early phase of the game-where the number of legal moves is largest-but became significantly stronger as the branching factor decreased.
MiniMax with alpha-beta pruning consistently outperformed plain MiniMax and often matched or surpassed MCTS under structured, low-randomness conditions. Domain-specific evaluators dramatically improved MiniMax’s performance. The trap-based evaluator was the most effective across nearly all conditions, confirming the strategic strength of forcing guaranteed captures in the late game. Strategies like Walls performed well only in deterministic openings, while Checkerboard and Noise strategies benefited from increased randomness.
When comparing MCTS against MiniMax augmented with domain knowledge, results were mixed. The Trap strategy remained a strong counter, while Checkerboard often matched MCTS at higher time limits. MCTS consistently beat the Walls strategy and gained a noticeable advantage as computation time increased, particularly under random or complex starting conditions.
Overall, MCTS excelled in dynamic, exploratory environments, whereas MiniMax-with the right heuristics-dominated more structured settings.
Limitations#
This study has several limitations. Only two board sizes were tested, and although they provided valuable contrast, a broader range might expose different behaviors. MCTS and the RL-based variant were limited by available computational resources; deeper simulations or longer training runs could materially change their performance. Similarly, MiniMax’s effectiveness depends heavily on evaluator quality, and our hand-crafted heuristics-while diverse-cannot cover all positional features relevant to advanced play.
Random initial moves were treated as uniform perturbations, but their distribution and structure were not analyzed in detail. More nuanced randomization schemes may reveal additional strengths or weaknesses. Finally, the evaluation focuses solely on win rates; complementary metrics such as move quality, stability, or error rates might offer a deeper understanding of algorithmic behavior.
Conclusion#
This study confirms that both MCTS and MiniMax have situational advantages in the Dots game. MCTS is highly effective in environments with large branching factors, unpredictable openings, or complex mid-game states. MiniMax, when enhanced with alpha-beta pruning and domain-specific evaluators, can outperform MCTS in stable or low-randomness scenarios-particularly when strategic motifs like traps are available.
No single algorithm clearly dominates across all conditions. Instead, their performance is context-dependent: MCTS thrives under uncertainty, while MiniMax excels when guided by strong heuristics and when the search space becomes more manageable.
Future work should explore hybrid approaches-for example, MCTS enhanced with domain knowledge or MiniMax supported by learned policies. Increasing computational resources for RL-based MCTS is especially promising and may yield agents stronger than any approach tested here. Additionally, studying how different random initialization patterns affect gameplay could provide further insight into algorithmic robustness.
Overall, the results demonstrate that combining principled search with domain expertise remains a powerful direction for complex board games like Dots.